목표: 글자가 깨지는 이유를 알아보자
요약
- 문제는 인코딩(encoding)
- 표준화된 인코딩 방법: Unicode

웹서핑 또는 문서를 열었을 때, 외계 문자를 본적 있을 것이다.

갑자기 컴터가 암에 걸린건가 싶고
바이러스에 감염된건가 싶은
어쨋든 굉장히 깨름칙함
문제는 인코딩(encoding)
컴퓨터랑 대화를 해야하는데,
컴퓨터는 0,1 밖에 모르고
내가 하는 말을 컴퓨터가 알아듣게 하기 위해 사용하는 방법이 인코딩이다.
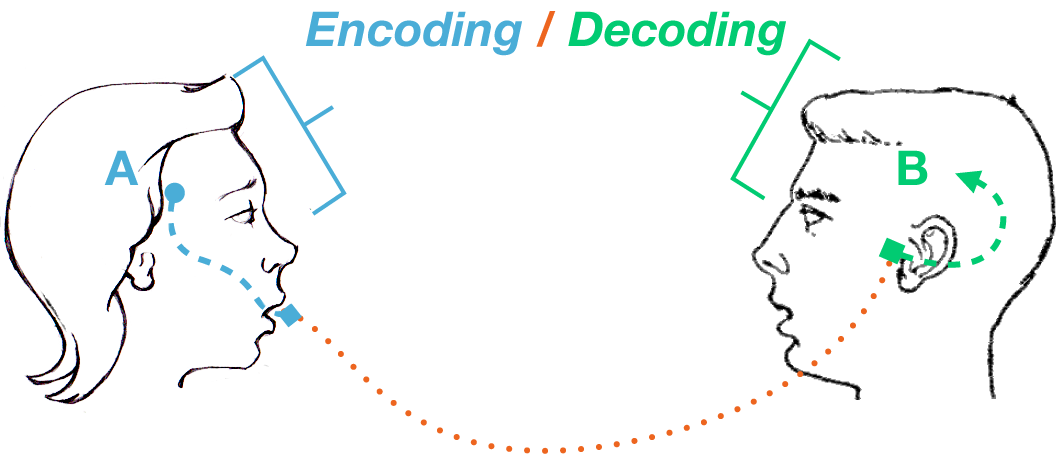
내가 컴퓨터에게 하고싶은 말을
해석, 변환해주는 일을 하는 것을 인코딩이라 한다.
style="display:inline-block;width:740px;height:200px"
data-ad-client="ca-pub-9512983930357661"
data-ad-slot="5785466884">

인코딩을 맞추면되지 뭐가 문제임?
hwp 문서를 word 에서 열어본적 있음?
반대로 word 문서를 hwp에서 열어본적 있음?
한번해보면 글자가 깨지나 안깨지나 알 수 있다.

같은 언어를 사용하더라도 프로그램, 시스템마다 다른 언어해석 방법을 사용하기 때문이다.

우리가 생각하는 것 보다 종류가 엄청 많다.
알아두면 좋은 인코딩 종류를 정리해놓았다.
| Name | Description | Example |
|
ASCII American Standard Code for Information Interchange |
7bit 인코딩 128개 문자열
라틴계열의 알파벳과 일부 특수기호를 표현하도록 만들어진 인코딩 방법 |
 |
| ISO-8859 |
8bit 인코딩 ASCII + 유럽권 언어
ISO-8859-1: 서유럽언어 ISO-8859-2: 동유럽언어 |
 |
|
EUC Extented Unix Code |
2byte 인코딩 ASCII + 완성형 한글 - ASCII는 1byte로 표현됨
주로 아시아권 언어(한국, 일본, 중국, 대만)
EUC-KR EUC-JP EUC-CN EUC-TW |
 |
|
CP Code Page |
마이크로소프트에서 EUC-KR을 개선, 확장하여 만든 것 949는 페이지 번호를 의미
한국: CP949 일본: CP932 중국어간체: CP936 |
|
|
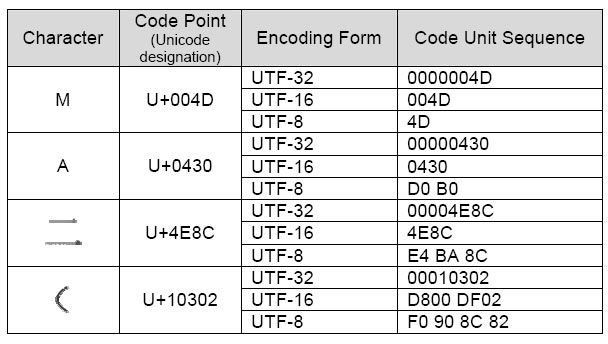
UTF Universal Coded Character Set + Transformation Format |
Unicode를 위한 가변 길이 문자 인코딩 UTF8(Universal Coded Character Set + Transformation Format – 8-bit)
UTF-8: 1-4bytes 인코딩(가변) UTF-16: 2-4bytes 인코딩(가변) UTF-32: 4bytes 인코딩
|
  |
표준화된 인코딩 방법: Unicode
Unicode에 대한 더 자세한 내용은
2019/12/03 - [놀고있네/i18n] - [Unicode] Unicode 란? (문자세트, 인코딩, 코드 포인트, 평면, 정규화) 🤪
2019/12/02 - [놀고있네/i18n] - [Unicode] Unicode 문자열이란? 🙄👮🏿♀️🍔
[Unicode] Unicode 문자열이란? 🙄👮🏿♀️🍔
목표: Unicode에서 정의하는 문자열을 알아보자 유니코드(Unicode)는 SW 국제화 요구사항 중 단연 필수적이라 할 수 있다. 2019/11/28 - [놀고있네/i18n] - i18n 이 뭔가요? SW 국제화가 뭔가요? 유니코드는 현존..
miaow-miaow.tistory.com
style="display:block"
data-ad-client="ca-pub-9512983930357661"
data-ad-slot="6440073001"
data-ad-format="auto"
data-full-width-responsive="true">
'🎪 놀고있네 > i18n' 카테고리의 다른 글
| [개발 시 유의사항] 쉽게 간과하는 것 - 1 (8) | 2020.01.06 |
|---|---|
| [개발 시 유의사항] 지나치게 한국적인 것 - 1 (4) | 2019.12.12 |
| [Unicode] Unicode 란? (문자세트, 인코딩, 코드 포인트, 평면, 정규화) 🤪 (1) | 2019.12.03 |
| [Unicode] Unicode 문자열이란? 🙄👮🏿♀️🍔 (1) | 2019.12.02 |
| i18n 이 뭔가요? SW 국제화가 뭔가요? 현지화가 뭔가요? (22) | 2019.11.28 |




댓글