목표: Unicode란 무엇이고, Unicode에서 알아두어야 할 용어들을 파악하자
- 문자 세트(Character set)
- 문자 인코딩(Character encoding)
- 코드 포인트(Code point)
- 유니코드 평면(Unicode Planes)
- 유니코드 정규화(Unicode normalization)

지난 게시글에서는 유니코드 문자열 종류에 대해 알아보았다.
2019/12/02 - [놀고있네/i18n] - [Unicode] Unicode 문자열이란? 🙄👮🏿♀️🍔
이번 게시글에서는 유니코드에서 필수적으로 알아둬야할 개념들을 정리해보았다.
일반적으로 유니코드에서는 각 코드 포인트를 표기할 때 16진수로 표기하되 접두어로 ‘U+’를 붙인다. 그리고 16진수가 0xFF 이하인 경우 0을 붙여서 ‘A’의 유니코드 0x41을 ‘U+0041’로 표기하는 것처럼 작성하여 표기한다.

1. 문자 세트(Character set)
문자 세트란 여러 언어가 사용할 수 있는 문자 집합이다.
Latin 문자 세트를 사용하는 언어는 영어와 대부분의 유럽의 언어이고,
Greek 문자 세트를 사용하는 언어는 그리스 언어이다.
그렇다면 한자는?
CJK(Chinese - Japanses - Korean, 중국어-일본어-한국어)를 통틀어서 이르는 말이며,
CJK 문자 세트는 공통적으로 한자의 영향을 받았다고 할 수 있는 중국어, 일본어, 한국어에서 사용된다.
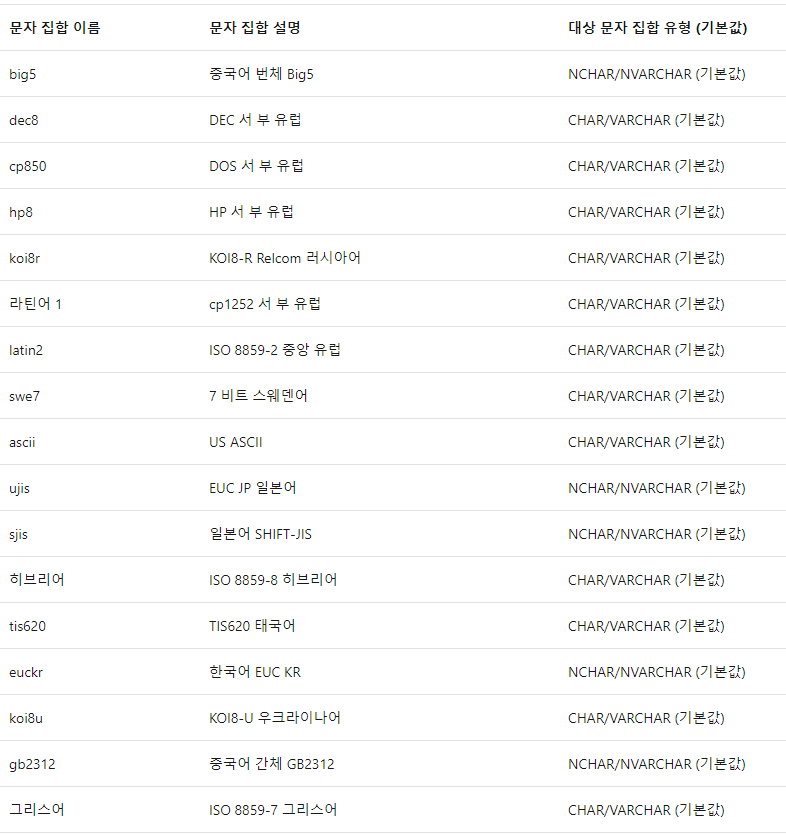
2. 문자 인코딩(Character encoding)
문자 인코딩이란 문자 세트를 컴퓨터나 시스템에서 표현할 수 있도록 하는 방법이다.
인코딩의 종류는 아래 게시글에 더 자세하게 나와있다.
2019/11/28 - [놀고있네/i18n] - [Characters] 글자가 깨져요
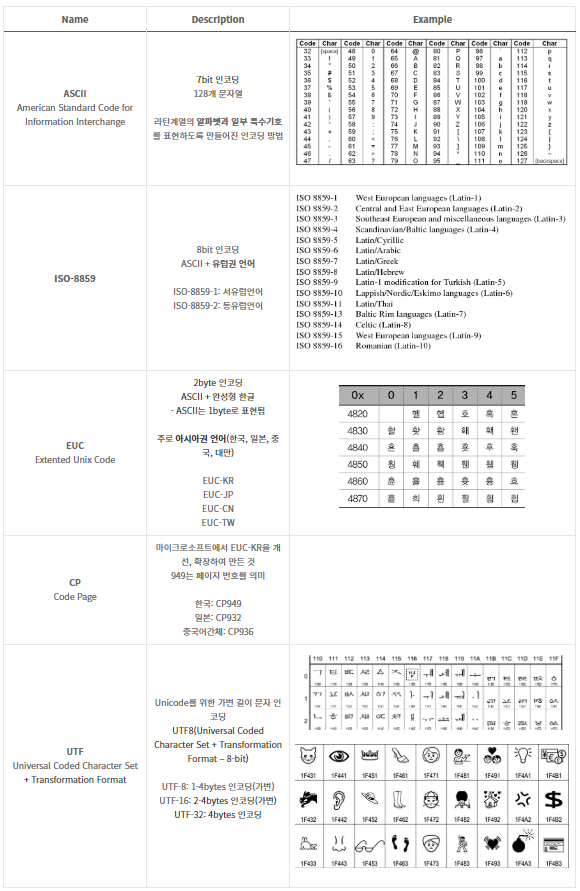
3. 코드 포인트(Code point)
코드 포인트는 문자열(Characters)을 대표하는 정수값이다.
문자열에 할당된 코드값이다. (1문자 1코드)
동일한 문자열에 할당된 코드값이더라도 인코딩의 종류마다 다르게 표현된다.
또한, 인코딩 바이트 수마다 다르게 표현된다.
유니코드 인코딩 방식인 UTF는 문자열을 표시하는 방법이 상이하다.
UTF-8: 1-4bytes 가변길이 인코딩
UTF-16: 2-4bytes 가변길이 인코딩
UTF-32: 4bytes 인코딩

따라서, 동일한 코드포인트를 갖고 동일한 인코딩 방식(UTF)를 사용하더라도
인코딩 바이트 폼에 따라 표현되는 형식이 다르다.
아래 그림을 보면 동일한 코드 포인트에 대해 UTF-8, UTF-16, UTF-32가 표시하는 형식이 다른 것을 확인할 수 있다.


4. 유니코드 평면(Unicode Planes)
유니코드 전체를 논리적으로 묶은 단위를 유니코드 평면이라고 한다.
한 평면은 65,536개의 코드 포인트가 존재하고, 총 17개의 유니코드 평면으로 구성된다.
엑셀파일을 떠올려보자.
엑셀파일에 17개의 시트가 존재하고, 한 시트에는 65,536개의 셀이 저마다의 코드 포인트를 가지고 있다.
이해가 좀 쉬운가? (나만 쉬운가;)
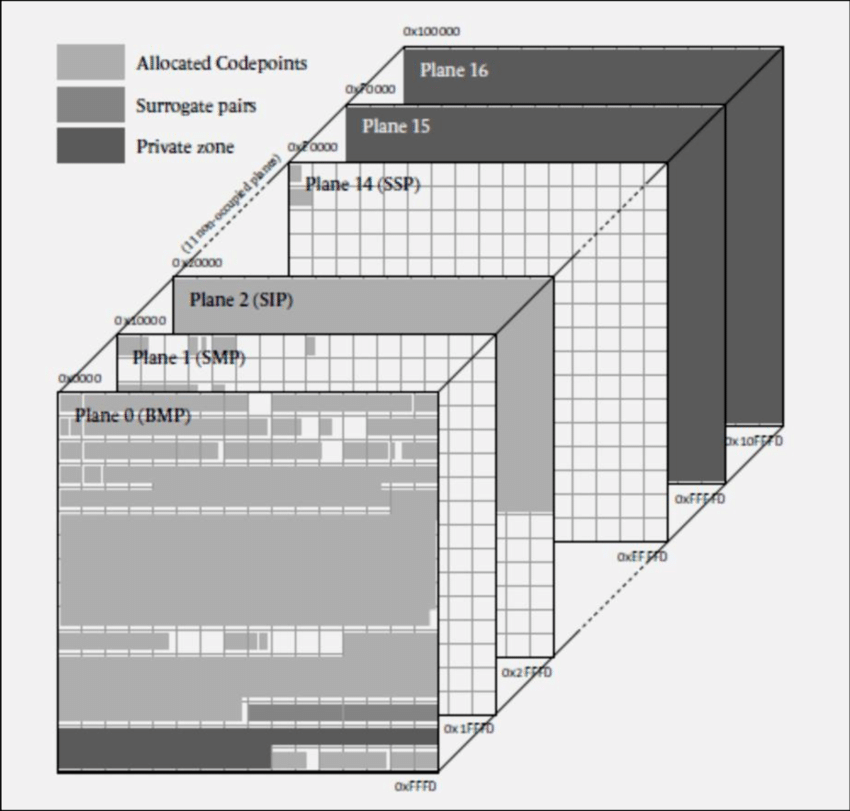
평면 중에서 몇개의 중요한 개념들이 있다. 😎

| 종류 | 설명 | 참고 그림 |
|
BMP (Plane 0) |
U+0000부터 U+FFFF까지 다국어 기본 평면으로 유니코드에서 많이 쓰이는 문자나 기호에 대해 배정한 평면 |
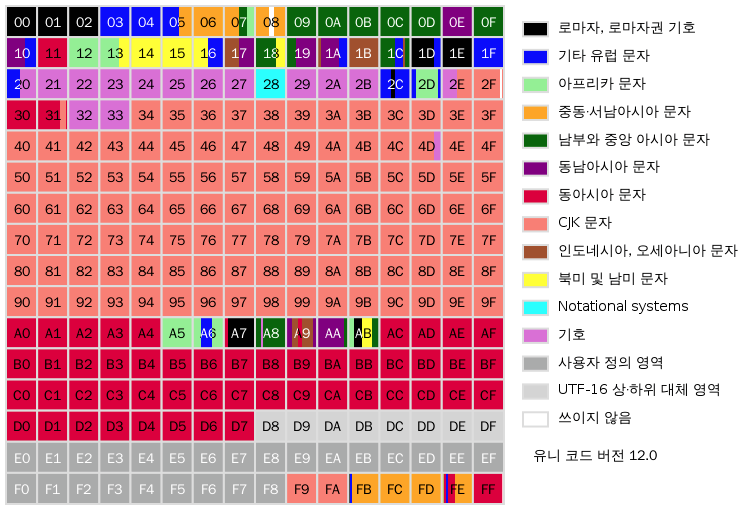 |
|
SMP (Plane 1) |
U+10000부터 U+1FFFF까지 언어 표기에 보조적으로 필요한 문자나 기호를 배정함 옛 한글, 이모티콘 |
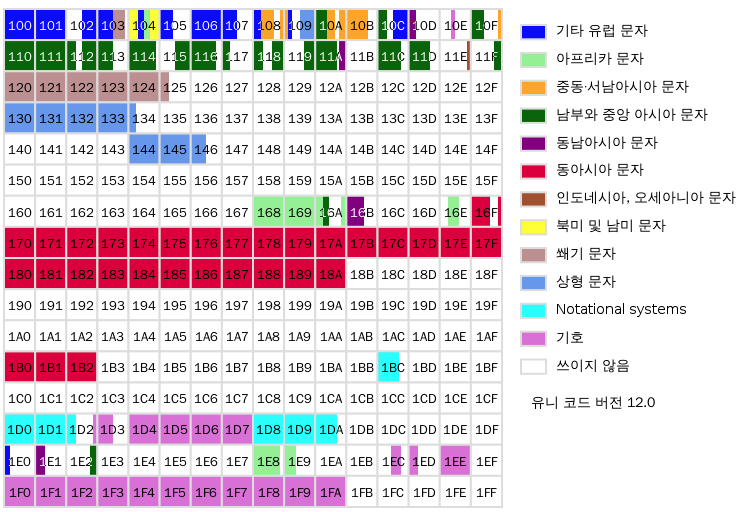 |
|
SIP (Plane 2) |
U+20000부터 U+2FFFF까지 CJK 표의문자(한자)가 배정되어 있음 |
 |
|
TIP (Plane 3) Tertiaty Ideographic Plane |
U+30000부터 U+DFFFF까지 갑골 문자, 금문, 소전 따위의 문자나 추가 한중일 통합 한자, 기타 옛 상형 문자 등을 위해 예약된 영역 |
문자 없음 |
|
SSP (Plane 14) |
U+E0000부터 U+EFFFF까지 태그 문자(tag characters)와 글리프 선택자(glyph selector)를 포함하고 있음 |
 |
|
SPUA-A/B (Plane 15-16) Supplementary Private Use Area-A or B
|
U+F0000부터 U+FFFFF까지 U+100000 - U_+10FFFF Private Use Area로 특정 단체나 개인이 자유롭게 문자 코드를 할당하여 사용할 수 있는 영역 |
문자 없음 |
5. 유니코드 정규화(Unicode normalization)
유니코드 정규화를 설명하기에 앞서, 결합 문자(combining marks)와 한글의 자모음 분리 등을 이해하고 가는 게 좋겠다.
결합 문자는 베트남어, 프랑스어, 독일어 등에서 쉽게 찾을 수 있다.
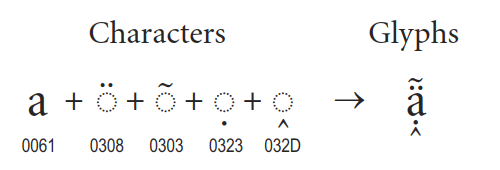
a 라는 라틴 문자열과 결합할 수 있는 부수적인 문자열을 combining marks 라고 한다.
(결합 문자보다는 combining marks라고 하는 것이 더 직관적이다.)

위의 그림을 보면 이해가 더 쉬울 것이다.

또 다른 의미로 결합? 조합?이 필요한 문자는 바로 한글을 예로 들 수 있다.

만약에 파일이름을 저장했는데, 저렇게 자음 모음이 분리되어 저장이 되었다면? (Mac OSX나 UNIX에서 파일명을 저장하고, Windows에서 해당 파일을 볼 때 다음 현상이 발생할 수 있다.)
그럼 나는 '강아지', '고양이'를 검색할 수 있을까? - 검색 및 문자열 비교 불가하다.
정규화의 필요성은 연속적인 코드를 사용해서 표현한 글자를 처리하는 방법을 다루고,
동등한 코드 포인트로 유니코드 문자열을 검색 및 비교하기 위해서 이다.
정규화는 문자열을 분해/결합(Decomposition/Composition)하는 2가지 방법과
정준(Canonical) 하고 호환(Compatibility)하는 2가지 방법이 조합되어 총 4가지 방법을 제공한다.
정준 등가(Canonical equivalence) 방식은 문자의 의미, 모양이 정확히 일치하는 지에 따라 문자열을 각각의 독립적인 코트 포인트로 인식하는 것을 말한다.
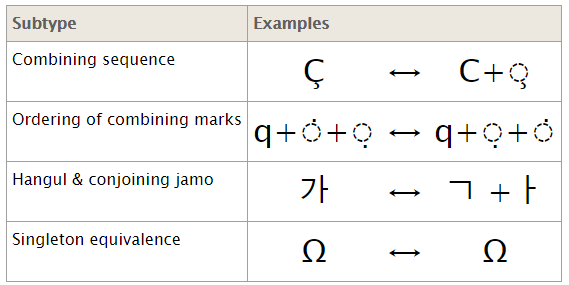
호환 등가(Compatibility equivalence) 방식은 문자의 의미는 같으나 모양이 다를 수 있는 경우에 따라 문자열을 호환가능한 유사 문자열로 인식하는 것을 말한다.
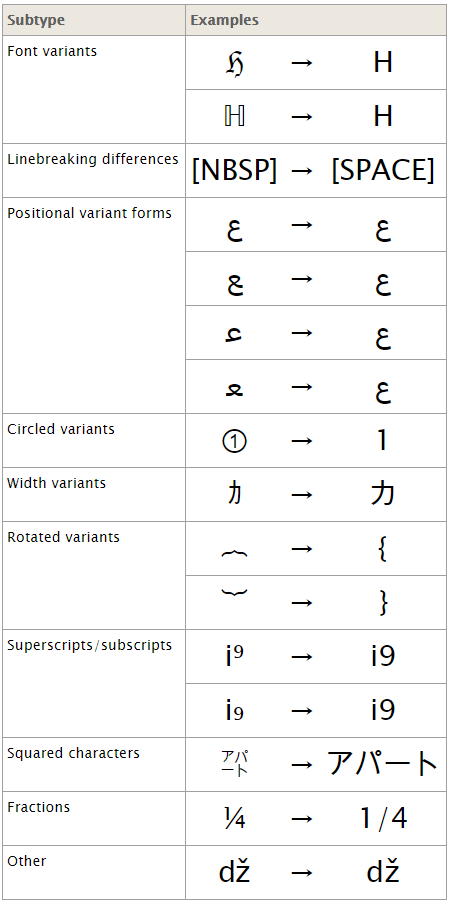
| 종류 | 설명 | 예시 |
| NFD (Normalization Form Canonical Decomposition) 정규화 양식 정준 분해 |
문자는 정준 분해 |
 |
| NFC (Normalization Form Canonical Composition) 정규화 양식 정준 결합 |
문자는 정준 분해 정준 등가성에 의해 다시 결합 |
|
| NFKD (Normalization Form Compatibility Decomposition) 정규화 양식 호환성 분해 |
문자는 호환성에 따라 분해 |
|
| NFKC (Normalization Form Compatibility Composition) 정규화 양식 호환성 결합 |
문자는 호환성에 의해 분해 정준 등가성에 의해 다시 결합 |
NFD는 Mac OSX, UNIX 시스템에서 주로 사용되며 모든 음절을 분해하여 저장하는 방식이다. (ㅍ + ㅔ + ㅇ + 1.jpg)
NFC는 Linux, Windows 시스템에서 주로 사용되며 문자를 있는 그대로 저장하는 방식이다. (펭1.jpg)
WC3는 웹용 정규화 표준 모델로 NFC를 선택했기 때문에 HTML5에서는 추가적인 NFC가 불필요하다.
'🎪 놀고있네 > i18n' 카테고리의 다른 글
| [개발 시 유의사항] 쉽게 간과하는 것 - 1 (8) | 2020.01.06 |
|---|---|
| [개발 시 유의사항] 지나치게 한국적인 것 - 1 (4) | 2019.12.12 |
| [Unicode] Unicode 문자열이란? 🙄👮🏿♀️🍔 (1) | 2019.12.02 |
| [Characters] 글자가 깨져요 (8) | 2019.11.28 |
| i18n 이 뭔가요? SW 국제화가 뭔가요? 현지화가 뭔가요? (22) | 2019.11.28 |




댓글